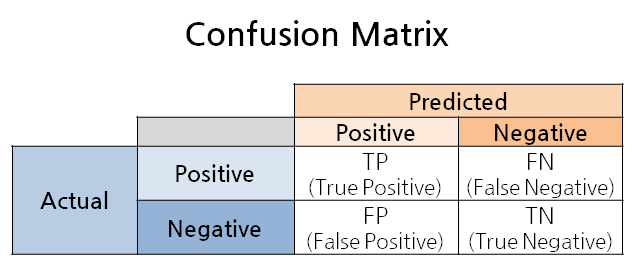
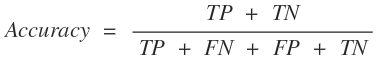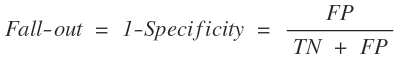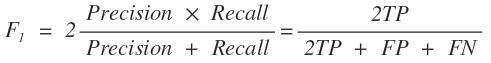일반적으로 Neural Network을 포함한 머신러닝을 통해 모델을 만든다고 할 때는
크게 지도 학습과 비지도 학습 방법이 있습니다.
지도 학습은 가르칠 데이터셋을 정리해서(labeled datasets) 학습을 시키는 방법이고, 비지도 학습은 (정리되지 않은) 데이터들을 그룹짓거나(군집) 새로운 데이터 생성 등을 할 수 있는 모델을 만드는 학습 방법입니다.
이 중 Image Classification Model은 지도학습 방법을 이용합니다.
따라서, 학습시킬 데이터를 미리 준비하고 가공하는 과정이 반드시 필요한데,
이 과정이 생각보다 훨씬 많은 시간과 노력이 필요합니다.
■ 데이터 수집
1. 분류하고자 하는 타겟 연예인 1차 선정
– 분류를 원하는 연예인 명단을 작성해 봅니다. 서비스 타겟 등에 따라 달라질 수 있음
– 사용층을 고려해서 연예인도 남녀노소 균형있게 고려할 필요가 있겠죠..
– NUGOO는 지금까지 국내 연예인 600~700명 정도의 데이터를 수집하면서 모델화 가능 여부 파악
– 수집된 데이터, 즉 사진의 수량과 질에 따라 최종 반영 여부 결정
2. 해당 연예인 사진 수집(프로그램)
– 간단한 웹 크롤링 프로그램 개발
– 연예인 이름으로 폴더를 만들어서 자동 수집 : 폴더 이름이 class label됨
– 사진을 수집하면서 사진에서 얼굴 영역만 1차 Crop하여 저장 : dlib, OpenCV 등 이용
– But, 아래 사진과 같이 얼굴영역을 잘못 인식하는 경우가 많고, 특정 연예인이 다른 사람들과 같이 찍은 사진이 많아 해당 연예인이 아닌 사진도 같이 Crop 되기도 합니다.
3-2. 사진 선별 작업(수작업)
– 3-1 과정에서 선별된 연예인별 사진을 최종 점검
– 이 과정에서도 가끔 서로 다른 연예인 사진이 나오는 경우도 있음
– 학습에 도움되지 않는 사진 제거(얼굴 정면이 많이 나오지 않은 사진 등)
4. 사진 수 조정 및 최종 타겟 연예인 선정
– 연예인별 사진 수를 점검하여 가능한 200 ~ 300장 범위가 되도록 조정
– class별 학습 균형을 위해 range를 줄일 수록 좋음
– 사진 수가 부족할 경우 argumentation 처리(flip 등)로 사진수 늘리기
– 그래도 기본적인 사진수가 부족한 경우 최종 타겟에서 제외
– 특정 연예인의 사진 수가 너무 많아도 한쪽으로 학습 편향이 생기기 때문에 사진 선별이 필요함
– NUGOO는 현재 380명의 연예인/유명인 분류
5. 사진 얼굴 변형(Transform)
– 모델의 성능을 높이기 위해 최대한 정면의 바른 포즈가 되도록 변형 작업이 필요함
– 실제로는 개인의 다양한 포즈(정면, 측면, 얼짱각도 등) 사진을 학습하는게 좋으나,
데이터가 부족하기 때문에 한가지 기준(정면 평형)으로 학습하는 것이 성능에 좋음
– 따라서, 새로운 사진을 inference할때도 얼굴 변형 과정 선행!
– 가로, 세로 기준점에 맞춰 눈, 코, 입이 평형 위치가 될 수 있도록 사진 변형하고,
– 눈썹과 턱선을 기준으로 2차 Crop
– dlib, OpenCV 등 이용
인공지능으로 알아보는 닮은 연예인 찾기 NUGOO는
deep+ lab에서 인공지능연구 및 분석을 목적으로 제작된 앱입니다.
현재 국내 연예인 및 유명인 380여명 / 8만6천여장의 사진을 학습한 모델로 서비스되고 있습니다.
머신러닝 알고리즘으로 인공지능 분류기 모델을 만드는 일련의 과정은 다음과 같습니다.
1) 대상 연예인 사진 수집 : 크롤링 등을 통해 학습을 위한 타겟 이미지 수집
2) 얼굴인식 및 추출(Detect & Crop) : 오픈 라이브러리 혹은 API를 통해 사진 내 얼굴 부분만 추출
3) 얼굴변환(Transform) : 학습 성능을 높이기 위해 얼굴을 기준점에 맞춰 변형(정렬)
4) 수치화(Representation) : 얼굴 사진을 수치로 표현(특정 좌표점으로 표현)
5) 분류기 모델 생성 : 인공지능 모델 설계와 학습 실험을 통해 최적의 모델 완성
원활한 서비스 이용을 위해서는
1. 얼굴 인식률을 높일 수 있도록 안경이나 모자 등은 벗어주세요.
2. 얼굴 영역이 너무 크거나 작으면 얼굴 추출이 안 될 수 있으니 적당한 거리에서 사진을 찍어주세요.
3. 정면이 아닌 사진은 인식률이 떨어질 수 있습니다.
4. 사진에 여러 명의 얼굴이 있을 경우 무작위로 하나의 얼굴만 추출됩니다~
새로운 기능
NUGOO V1.1.0
뽐내기(자랑하기) 기능추가 되었습니다.
이제 비교결과를 다른사람과 공유할 수 있습니다.
기타 UI가 변경되었습니다.
History
– 2017.05.15 얼굴비교 서비스 추가 개시
– 2017.05.08 연예인/유명인 250명 추가, 인공지능 분류기 머신러닝 알고리즘(DNN) 변경
– 2017.04.26 닮은 연예인 찾기 누구(NUGOO) 정식버전(free) 출시 : 서비스 개선 및 뽐내기 기능 추가
– 2017.04.11 닮은 연예인 찾기 누구(NUGOO) Lite버전(free) 출시 : 130명 대상 인공지능 분류기 모델 서비스